
Introducing BRAG: High Performance RAG Model Trained in $25
Cost effective family of SLMs(small language models)


We are excited to announce the release of our RAG models, collectively known as BRAG. In this update, we share our findings, provide a brief technical report on model selection, training, evaluation, metrics, and outline our future roadmap. Each model is trained in less than $25.
Our models surpass Cohere’s Command R+, Qwen2, Llama3.1, and Llama3 Instruct models in performance. They closely match the performance of GPT-4-Turbo and Nvidia’s ChatQA-1.5-8B.
This is a joint work done by Ravi Theja and Pratik Bhavasar. Feel free to reach out to us for any queries.
What is BRAG?
BRAG is a series of SLMs trained for RAG (Retrieval Augmented Generation). We primarily trained & evaluated them for English but base models have multi-lingual capability.

(Performance for Command-R-Plus, GPT-4-Turbo and ChatQA-1.5-8B are as per the ChatQA paper.)
Models

We release 4 models - 3 SLM and 1 Ultra SLM.
- Instruct finetuning on Qwen2–7b-instruct under Apache 2.0 license.
BRAG-Llama-3.1-8b-v0.1
- Instruct finetuning on Llama-3.1–8b-instruct under Llama3.1 license.BRAG-Llama-3-8b-v0.1
- Instruct finetuning on Llama-3–8b-instruct under Llama3 license.BRAG-Qwen2-1.5b-v0.1
- Instruct finetuning on Qwen2–1.5b-instruct under Apache 2.0 license.
Technical Report
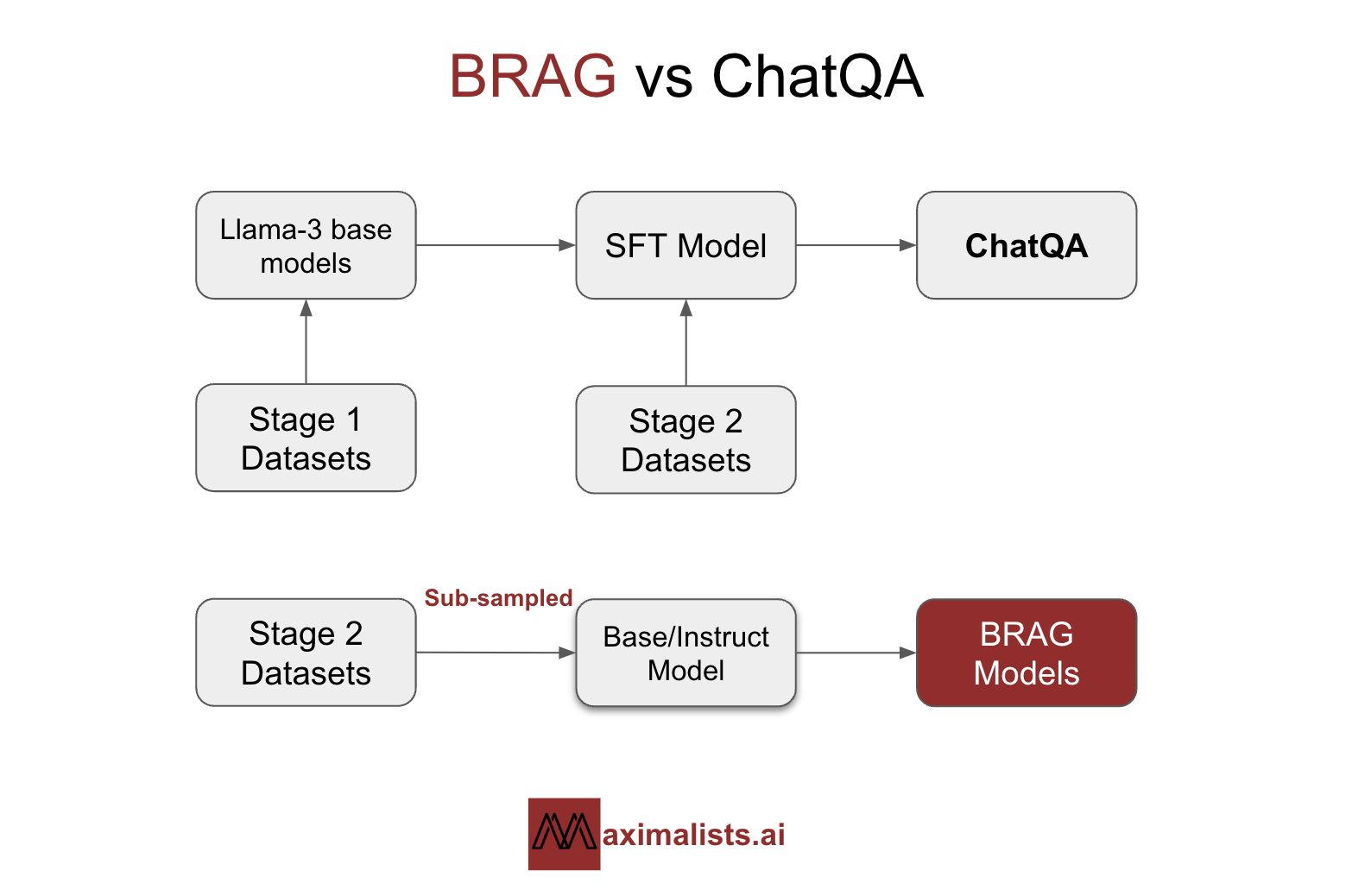
We discovered the ChatQA paper from Nvidia showcasing an approach of building a RAG model using Llama3 models with a two-stage fine-tuning process. The first stage involved general instruction datasets, while the second focused on RAG-specific datasets.
They also shared their second-stage training data and introduced a new benchmark, ChatRAG-bench, for evaluating chat performance with text and tabular datasets. This provided us with a valuable framework and target for our experiments.
Our goal was to conduct cost-effective experiments to match the performance of Nvidia's Llama3-ChatQA-1.5-8B model. With only $1,000 in credits from Modal Labs, and given that an experiment costs $10 - $50, we had around 30 experiments to work with. Therefore, we decided to use a subsampled dataset, experiment with various data mixes, and utilize smaller, more efficient models.
Model Selection
We carefully selected 1.5B, 7B, and 8B models for our experiments based on results from open benchmarks.
Why 1.5B, 7B/8B, and not 70B?
The 1.5B models offer a great balance between performance and efficiency.
The 7B and 8B models provide enhanced capabilities for complex tasks requiring long context, tabular and math understanding.
While 70B models are powerful, we aim to achieve comparable performance with smaller, more efficient models. Additionally, we are constrained by limited computational resources for 70B models.
Below are the base/instruct models we used for fine-tuning.
Qwen2-1.5B (base)
Qwen2-7B-Instruct
Llama-3.1-8B-Instruct
Llama-3-8B-Instruct
Evaluation Benchmark
We use ChatRAG-Bench which is a collection of datasets designed to evaluate the model's capability in conversational QA and RAG. It covers a wide range of documents and question types, requiring models to generate responses from context, comprehend and reason over tables, conduct arithmetic calculations, and indicate when questions cannot be answered within the context.

Training Datasets
The composition of the dataset can significantly impact model performance. We dedicated considerable time to analyze ChatRAG-bench to identify equivalent characteristics in ChatQA-Training-Data. The evaluation datasets and associated metrics emphasize the need for concise outputs to achieve higher F1 scores by effectively utilizing both the generated responses and the ground truth.
To optimize performance, we conducted numerous experiments with various dataset combinations. Our approach was twofold: we selectively chose datasets and then subsampled from those. This strategy was crucial in managing costs effectively. Initially, working against scaling laws proved beneficial.
Different datasets exert varying degrees of influence on performance metrics, which is contingent upon the foundational capabilities of the model. Consequently, we made efforts to exclude training datasets that did not contribute significantly to performance improvements.
Below is a list of the datasets included in ChatQA-Training-Data.

The ChatQA models underwent a two-stage training process:
1. Stage 1: The models were trained using Supervised Fine-Tuning (SFT) on a large dataset.
2. Stage 2: Training continued with ChatQA-Training-Data.
By employing parameter-efficient finetuning on a significantly smaller subsampled dataset from the same sources, we achieved comparable performance.
Training Methods

We primarily experimented with LoRA and QLoRA. In this section, we provide a brief overview and share several techniques we employed while using these methods during the training stage.
In LoRA (Low-Rank Adaptation), the parameter r represents a hyperparameter that defines the rank of the low-rank matrices utilized for adaptation. A smaller value of r simplifies the low-rank matrix, resulting in fewer parameters to learn during the adaptation process. This can lead to faster training and reduced computational demands. However, decreasing r may also diminish the matrix's ability to capture important task-specific information.
The alpha parameter governs the magnitude of the modifications made by the LoRA layer to the model's existing weights, expressed as alpha * (x @ A @ B). This influences how the newly trained parameters affect the model's output. A higher alpha value leads to more significant adjustments in the model's behavior, while a lower value results in subtler changes. It's worth noting that an excessively high alpha can contribute to catastrophic forgetting of previously acquired knowledge.
QLoRA is a variant of LoRA that operates by quantizing the precision of the weight parameters in the pretrained LLM down to 4-bit precision. Traditionally, model parameters are stored in a 32-bit format, but QLoRA compresses them to 4 bits. This quantization significantly reduces the memory footprint of the LLM, enabling finetuning on a single GPU. As a result, QLoRA allows for the operation of large language models on less powerful hardware, including consumer-grade GPUs.
Recommendations for effective use of LoRA and QLoRA
1. Set alpha to twice the value of r: Based on the experimentation of other researchers, we recommend maintaining alpha at double the value of r to strike an optimal balance between adaptability and stability.
2. Keep r as small as necessary: Initially, we experimented with higher values of both r and alpha, anticipating superior results. However, through several iterations, we found that smaller values yielded performance that was just as effective.
3. QLoRA is comparable to LoRA: We conducted tests comparing model performance using LoRA against QLoRA. Remarkably, we found that there was no discernible benefit from using LoRA over QLoRA, indicating that QLoRA is equally capable.
Fine-tuning Base vs Instruct Models
In our experimentation, we explored the fine-tuning process for both base and instruct models. Base models are pre-trained language models without task-specific training, while instruct models have already undergone instruction-following fine-tuning.
In general, it is observed that fine-tuning base models often requires more extensive training and data to achieve task-specific performance. However, it offers greater flexibility in shaping the model's behavior and output style. Instruct models, on the other hand, generally require less fine-tuning to adapt to specific tasks, as they already understand instruction-following patterns.
Our experiments revealed key factors in choosing between base and instruct models - dataset size and quality. We found that in case of Qwen1.5B, finetuning base model performed better than finetuning Instruct model but in Qwen7B, Llama3 8B, Llama3.1 8B finetuning instruct models gave better performance.
Learning: These findings underscore the importance of empirical testing across different model sizes and architectures, as the optimal choice between base and instruct models can vary depending on the specific use case, dataset and model characteristics.
Metrics
We evaluate our models on the ChatRAG-Bench evaluation dataset using the following metrics, as suggested in NVIDIA's ChatQA paper:
F1-Score: F1-score is calculated based on token matching with the ground truth answer. It measures the overlap between the model's generated answer and the correct answer at the token level. F1 is the harmonic mean of precision and recall. F1 score is used as evaluation metrics on all datasets except ConvfinQA.
Exact Match Accuracy: This metric measures the percentage of model responses that perfectly match the ground truth answer, word for word. Exact Match Accuracy as evaluation metric for ConvFinQA dataset.
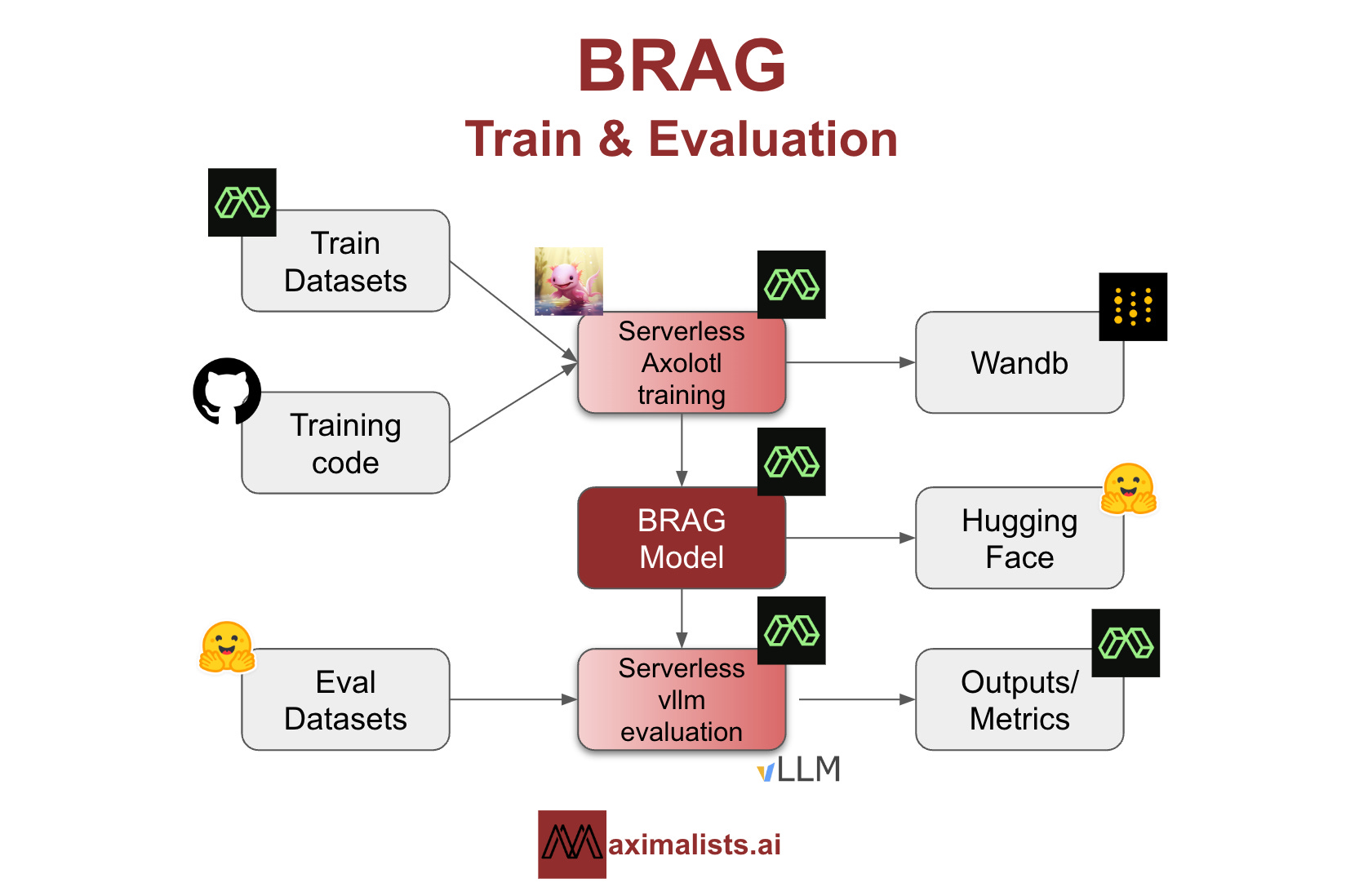
Training & Evaluation Infrastructure
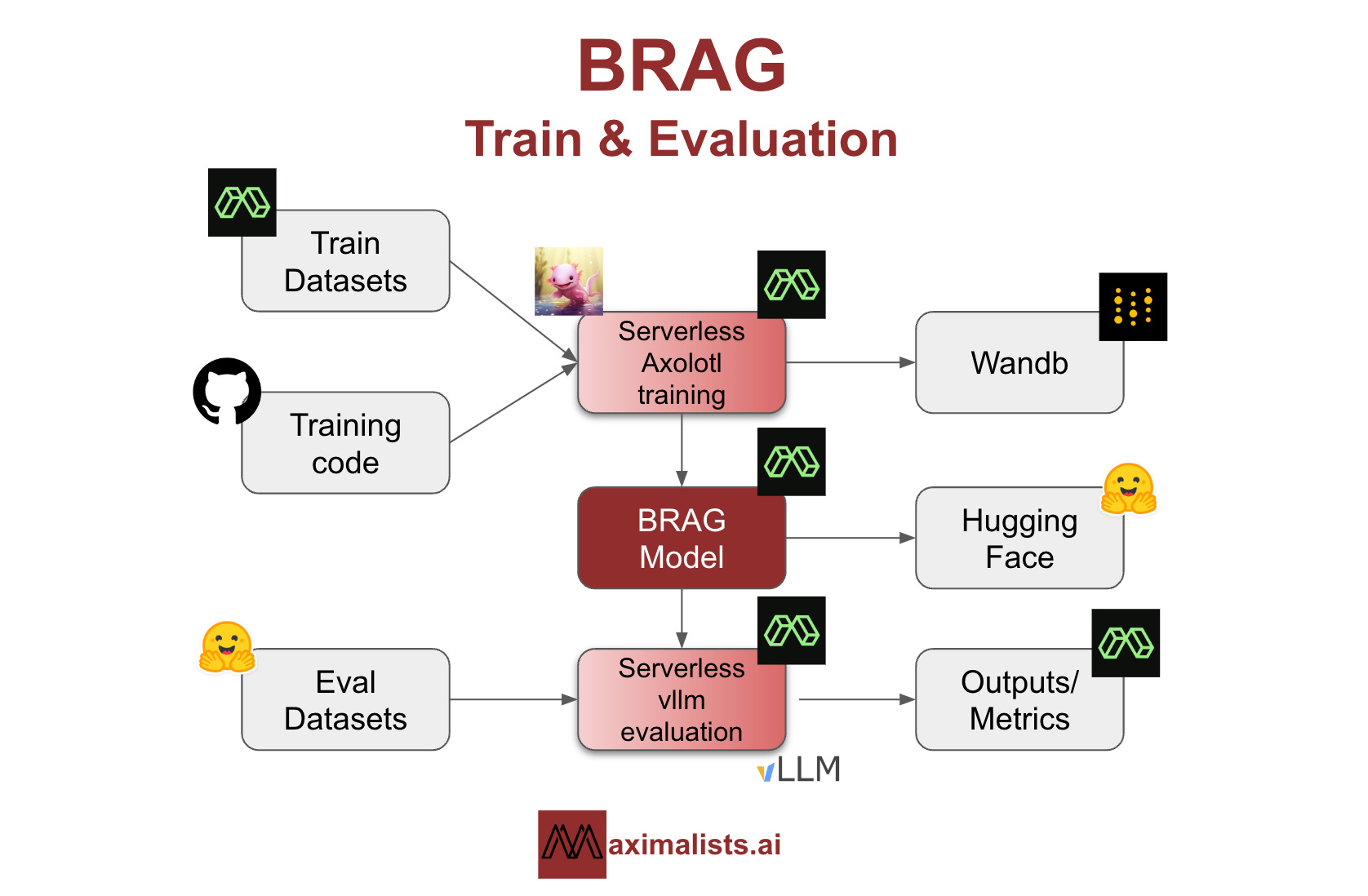
Streamlining training and evaluation infrastructure is crucial for faster and cleaner iterations. With this in mind, we used Modal Labs (GPU infrastructure), Axolotl (fine-tuning framework), and Wandb (monitoring). This combination streamlined our workflow which significantly accelerated our iteration process.
Axolotl
Axolotl is a tool designed to simplify AI model fine-tuning, offering support for a wide range of latest models and training methods. Key features include:
Latest models: Llama3.1, Llama3, Qwen2, Gemma, and more
Multiple PEFT methods: LoRA, QLoRA, and others
Dataset formats: ChatML, ShareGPT.
Single or multi-GPU support via FSDP or DeepSpeed
Integration with logging platforms: Wandb and MLFlow for tracking results and checkpoints
Modal Labs
Modal is a serverless cloud platform that simplifies AI model development and deployment by abstracting away infrastructure concerns. We chose Modal for our project due to its comprehensive features:
Serverless GPU infrastructure: No need to manage servers or clusters
Support for various GPU resources: H100s, A100s (80GB/40GB), A10g, and others
Seamless integration with Axolotl for fine-tuning
Built-in storage for evaluation metrics, system metrics, and logs
Tracking of GPU runtime and inference statistics
We trained on 4 H100’s and evaluated with H100/A100/A10g as per the model size.
Wandb
We chose Wandb as our monitoring/logging platform for its integration with Axolotl.
How We Trained for Less Than $25?
Our optimal dataset configuration completed training on four H100 GPUs within just one hour for a single epoch. With the cost of using these GPUs at $5.92 per hour on Modal Labs, this efficient setup enabled us to train the 7B/8B models for only $25, and the 1.5B models for about $10.
We conducted numerous experiments to achieve this configuration of a smaller dataset mix, which also allowed us to train additional models at reduced costs.
Model Usage
Inference dependencies - use the latest transformers and accelerate.
For detailed setup, refer to models on Hugging Face.

Training & Evaluation Issues
We encountered significant challenges in training data and evaluation methods. These arise from mismatches between training and evaluation datasets, and limitations in current metrics. Addressing these issues is crucial for enhancing model performance and accurately assessing capabilities in future iterations.
Training Data Issues
1. Long Documents Handling
Models in training were primarily exposed to datasets like DROP, NarrativeQA, and NewsQA, which consist mostly of medium to long narrative texts. However, these datasets might not adequately prepare the model for handling significantly long documents such as those in INSCIT and Doc2Dial. The discrepancy in document length poses a challenge, as it can lead to difficulties in adequately segmenting and processing extended texts during evaluation.
2. Tabular Data Processing
A key challenge with training data like DROP, Quoref, and SQuAD, which do not include table-based information, is that the model may struggle when faced with tabular data during evaluation. Evaluation datasets such as ConvFinQA, TAT-QA, and SQA contain tabular data requiring precise interpretation which the model may not be well-equipped to handle due to limited exposure during training. Similarly, Hybridial evaluation dataset has both text and tables, including such dataset in training data improves the evaluation metrics.
3. Domain Specialization
Models trained predominantly on instruction datasets may not perform optimally on domain-specific evaluation datasets such as DoQA(travel, cooking, movies) and ConvFinQA(finance). The lack of focus on industry-specific terminology and conventions in the training data can hinder the model's ability to understand and respond to domain-specific queries effectively.
4. Unanswerable Questions
Training datasets like SQuAD 2.0 include unanswerable questions, but the focus remains largely on providing correct answers. The model might struggle to identify and appropriately respond to unanswerable questions in evaluation datasets like QuAC and DoQA, especially since handling such inquiries necessitates adaptability and nuanced understanding, which might not be fully developed without substantial targeted training.
Evaluation Metric Issues
F1 Score Limitations
The F1 score used for ChatRAG-Bench, although a widely accepted metric, has its limitations—especially in capturing the semantic nuances and contexts of generated responses.
Sentence Variability
Different answers like "No, she was not happy," "No, she was sad," and "No, she wished she looked like them" might all receive an F1 score of 1.0 despite significant variations in context and semantic relevance.
Partial Matches
Answers that do not perfectly align with the ground truth, such as "She used a can of orange paint to paint herself orange" versus "she painted herself," will score less than 1 despite their relevance, highlighting the token-level matching imperfection.
These limitations can result in misleading evaluations of model performance, as the F1 score may not accurately reflect the quality and relevance of the answers generated by the model. This underscores the need for a more holistic and context-aware metric to better gauge model competence.
What next?
The next steps involve making several improvements and adding new capabilities, essential for boosting overall functionality.
Improve RAG performance to provide more accurate results
Improve tabular performance for better data handling and analysis
Introduce citations generation for interpretability results
Query rewriting to improve search accuracy and relevance
Acknowledgements
We are grateful for the Mastering LLMs: A Conference For Developers & Data Scientists course from Hamel Husain and Dan Becker, which provided us with $1,000 in Modal Labs credits for our project. Special thanks to Charles Frye from Modal Labs for his support.
Appendix
The following table presents detailed metrics for various evaluation datasets across different models.

 | A guest post by
|
Is the code for BRAG on GitHub and can we try it? Please let me know. Thanks.